Unit 06: Comparing Statistical Distributions
Contents
Unit 06: Comparing Statistical Distributions#

Author: Dr Antonia Mey
Email: antonia.mey@ed.ac.uk
Learning Objectives#
Be confident in computing statistical properties of a dataset
Know how to plot a histogram and box-plot
Use the Student’s t-test in Python to compare datasets
Recap of how to read data
Recap of how to plot basic data
Table of Contents#
Summary of how to Read Data Files
1.1 Inspecting files
1.2 Reading Files with NumPy
1.3 Reading Files with Pandas
1.4 Basic Reading with Python
1.5 TasksHandling Datasets and Statistics
3.1 Working with Measurement Data
3.2 TasksComparing two Distributions
4.1 The Gauss Distribution
4.2 Box Plots
4.3 Student’s t-test
4.4 Tasks
Further reading for this topic#
More exhaustive reading on statistics: https://philschatz.com/statistics-book/contents/m46925.html
Link to documentation:#
Loading files#
Statistics#
np.median
np.std
Jupyter Cheat Sheet
To run the currently highlighted cell and move focus to the next cell, hold ⇧ Shift and press ⏎ Enter;
To run the currently highlighted cell and keep focus in the same cell, hold ⇧ Ctrl and press ⏎ Enter;
To get help for a specific function, place the cursor within the function’s brackets, hold ⇧ Shift, and press ⇥ Tab;
import sys
import os.path
sys.path.append(os.path.abspath('../'))
from helper_functions.mentimeter import Mentimeter
import numpy as np
import matplotlib.pylab as plt
import pandas as pd
1. Which method should I use for reading a data file?#
In Python there are many different was to read a file and multiple methods will work for a file. In the following is a quick overview of the different methods you have encountered so far and how to decide which is the best method to use for a given file you are working with.
1.1 Inspecting the file#
The first step is to look at the content of the file before you try and read it.
You can do so by opening the file with a text editor.
Some files may be large, so using something like
!headmaybe better
head:
Gives you the first 10 lines of your file.
It is a Linux command that will work in a Jupyter notbeook if you use
!before this command.
!head data/example_1.mol
!head data/example_2.smi
!head data/example_3.csv
!head data/example_4.csv
1.2 Reading a file with NumPy#
Out of all the file examples data/example_4.csv will be the best for using numpy. It only contains numerical data and has a header that can be easily skipped.
data = np.loadtxt('data/example_4.csv', skiprows=1, delimiter=',')
print(data)
np.loadtxt(), requires explicit information on which rows you want to skip, because they represent headersnp.loadtxt(), requires explicit information on the delimiter used in the file.a
numPyarray is returned
data1 = np.genfromtxt('data/example_4.csv',delimiter=',' )
print(data1)
np.genfromtxt()tries to be a bit cleverer and will generate also incomplete data.
1.3 Reading a file with Pandas#
data/example_3.csv is a good example to use with Pandas. This is because it uses a mixture of datatypes. You have a date in the first column and a floating point in the second column.
df = pd.read_csv('data/example_3.csv')
print(df)
pd.read_csv()has many option to customise the reading of a file and can manage many exceptions by default. Reading the documentation here is your friend.It returns a pandas data frame.
1.4 Reading a file using basic Python#
Not all files are data files. A lot of chemistry files are quite complicated. In this case sometimes a file needs to be read ‘manually’. Or you need to find a suitable existing Python package that can help with reading typical chemistry files.
Examples of such files are data/example_1.mol and data/example_2.smi. The first one is a mol file and the second a smiles string. If you are unsure here is an example of how you can read these:
f = open('data/example_2.smi', 'r')
lines = f.readlines()
print (lines)
f = open('data/example_1.mol', 'r')
lines = f.readlines()
print (lines)
data = []
for line in lines:
data.append(line.strip().split()) # strip removes end of line characters and split split things into arrays.
print(data) # now each line is an array of string elements
Tasks 1#
Look at the file: data/GC2_stage1_Free_Energy_Set_1.csv
What method is best for reading this file?
Does it have a delimiter? If so what is it?
# FIXME
Click here to see solution to Task.
!head data/GC2_stage1_Free_Energy_Set_1.csv
The best method would be pandas as the columns are a mix of strings and numerica data The delimiter is a comma.
Read the file data/GC2_stage1_Free_Energy_Set_1.csv with the best method for reading it from task 1.1. Could you still read it using a different method?
# FIXME
Click here to see solution to Task.
df = pd.read_csv('data/GC2_stage1_Free_Energy_Set_1.csv', delimiter=',')
print(df)
# You could use np.genfromtext, but this makes it more complicated.
data = np.genfromtxt('data/GC2_stage1_Free_Energy_Set_1.csv', delimiter=',', skip_header=1)
# the first column will be garbage because it is the receiptID which is a string
print(data[:,1:]) # only display from second column (remember that python starts counting from 0!)
Check the content of your file using e.g.
!head, or by opening the file using a text editornp.loadtxt(‘filename’), ornp.genfromtxt(‘filename’)If the file contain a header, but otherwise numerical values that are separated by a delimiter
You can skip the header by using
skiprows = number of rowsYou can specify a delimiter with
delimiter=’,’
pd.read_csv(‘filename’)Use this if you have tabular data, such as you would find in excel with a header row that you want to use as information
The data is a mixture of numerical and other datatypes
There is data missing, managing
NaNwith pandas is much easier.
f=open(‘filename’, ‘r’)If the file seems quite unstructured you may need to clean the data manually then use a generic file reader and read the file line by line.
You will need to use tools such as
line.strip()orline.split(’ ‘)to clean the data.
Reading a file can also be referred to as parsing a file.
2. Plotting Recap#
Test your understanding of plotting data#
# generating some data for plotting, use x and y to test things out
def f(t):
return np.exp(-t) * np.cos(2*np.pi*t)
x = np.arange(0.0, 5.0, 0.1)
y = f(x)
How to plot data?#
# Use this cell to try and plot x and y so you can answer the question below
We are using the following question with mentimeter here:
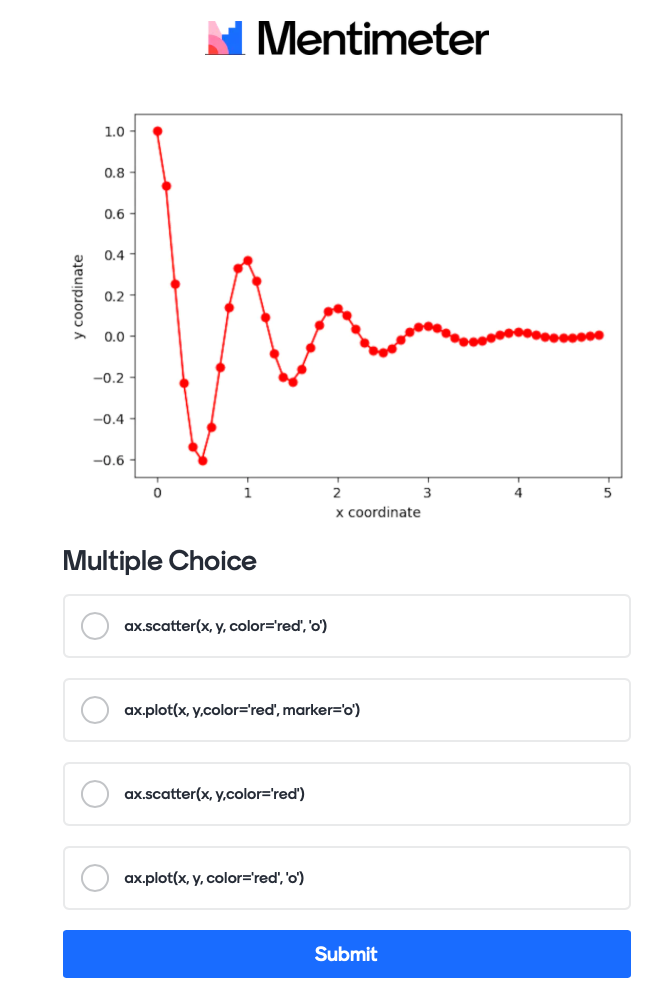
The actual code for this would like this:
Mentimeter(vote = 'https://www.menti.com/link_to_menti').show()
How do you add axis labels correctly?#
# testing adding axis labels
We are using the following question with mentimeter here:
The actual code for this would like this:
Mentimeter(vote = 'https://www.menti.com/link_to_menti').show()
How do you plot data using a logarithmic x-axis (you have not been taught this, try and figure it out)#
# test showing axis in logarithmic scale
We are using the following question with mentimeter here:
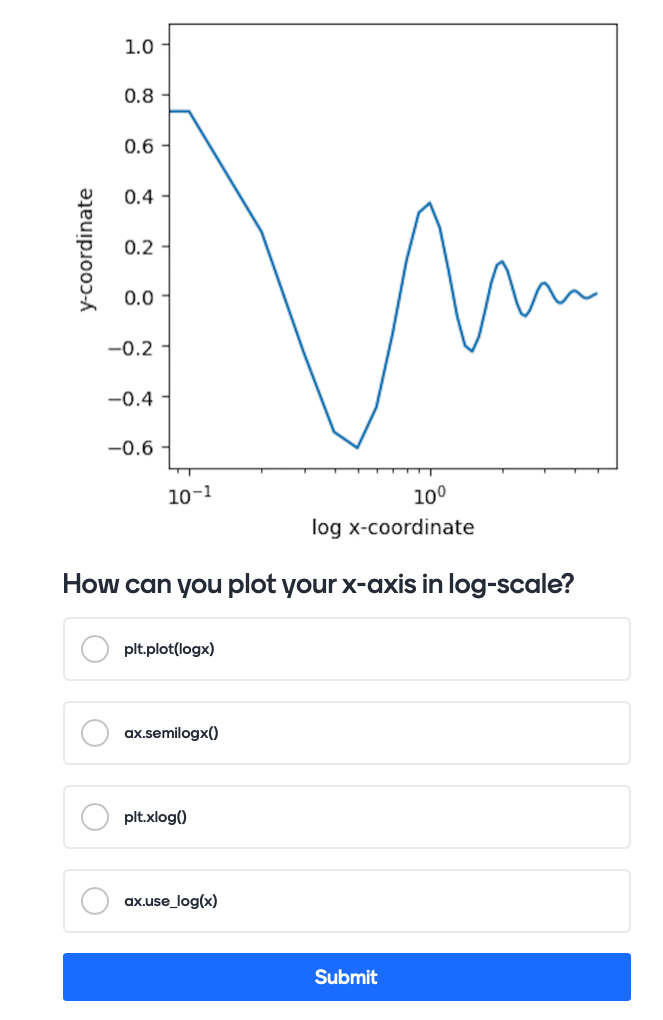
The actual code for this would like this:
Mentimeter(vote = 'https://www.menti.com/link_to_menti').show()
Additional practice material:#
If you do not feel confident enough with plotting and loading data yet, you can practice a little with this notebook after today’s session in your own time.
3. Handling datasets and statistics#
3.1. Working with measurement data#
The file data/air_quality.csv contains measurements of the concentration of Cobalt in the air in Westminster taken in the last year. We want to look at the mean, median, and standard deviation of this data set through a series of short tasks.
The population mean of a dataset gives you the average value by summing all datapoints and dividing by the number of data points#
where \(N\) is a number of samples and \(x_i\) is the ith sample in a dataset \(X\). In a measurement, as \(N\) increases the mean becomes closer to the ‘true’ value.
mu = np.sum(x) / len(x)
or as a np.mean(x).
For a dataset \(X\) of \(N\) elements ordered from smallest to greatest the median is given by:
\(\mathrm{median}(X) = x_{(N+1)/2}\) if \(N\) is odd and
\(\mathrm{median}(X) = \frac{x_{(N/2)}+x_{(N/2+1)}}{2}\) if \(N\) is even.
np.median(x) to compute the median with numpy.
And using Python code you can write it as:
sigma = np.sqrt( np.sum( ( x - np.mean(x))**2 ) / len(x) )
np.std(x) to compute the standard deviation with numpy.
Tasks#
Read the file data/air_quality.csv and remove the NaN measurement points and compute the mean, median and standard deviation of the dataset.
# Task: Test out the solution in this cell:
Click here to see solution to Task.
import pandas as pd
data = pd.read_csv('data/air_quality.csv')
mean = np.mean(data['Co measured in V ngm-3'].dropna())
std = np.std(data['Co measured in V ngm-3'].dropna())
median = np.median(data['Co measured in V ngm-3'].dropna())
print(f"The mean Co concentration is {mean:.3f} V ngm-3, the median Co concentration is {median:.3f} V ngm-3, and the standard deviation is {std:.3f} V ngm-3.")
# Task: Test out the solution in this cell:
Click here to see solution to Task.
import matplotlib.pylab as plt
plt.hist(data['Co measured in V ngm-3'].dropna(), bins=30)
plt.xlabel(r'Co V ngm$^{-3}$')
plt.ylabel('Count')
Use Google if you are unsure and give an answer in markdown
# Task: Test out the solution in this cell:
Click here to see solution to Task.
Standard deviation (STD) measures the dispersion of a dataset relative to its mean.
STD is used frequently in statistics
The standard error of the mean (SEM) measures how much discrepancy is likely in a sample’s mean compared with the population mean.
The SEM takes the STD and divides it by the square root of the sample size.
The SEM will always be smaller than the SD.
4. How do I know if two distributions are the same?#
Plotting a histogram of the data tells you something about the underlying distribution of the data.
There are many different types of distributions, here are some examples:
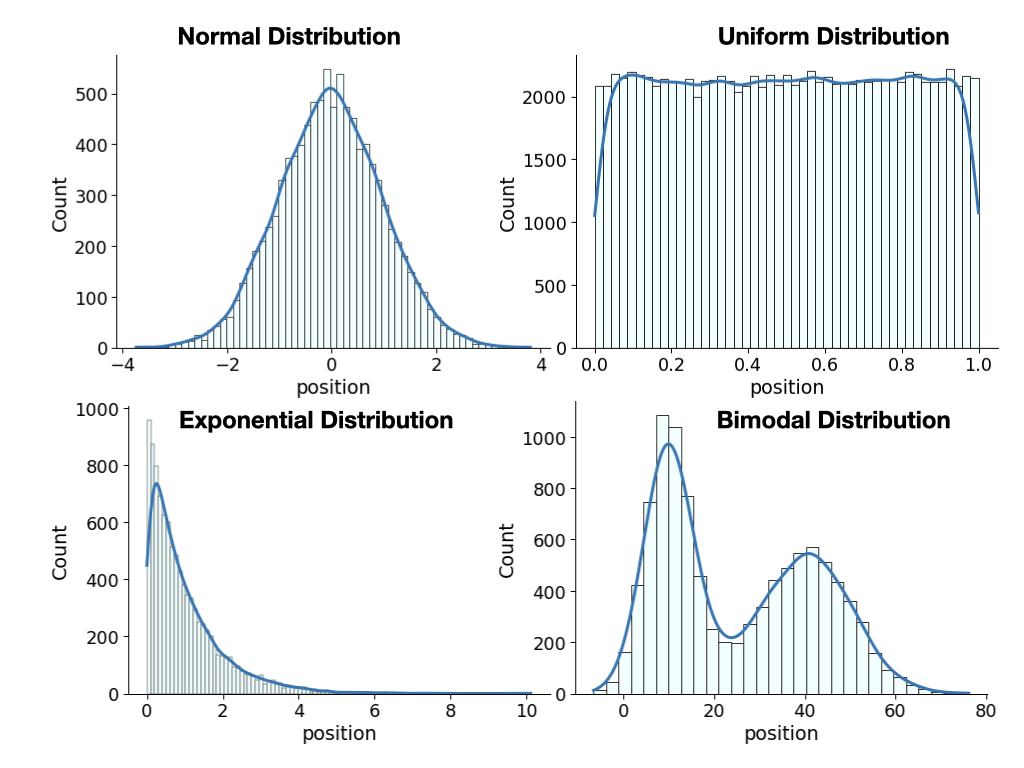
Click here to see the code used to generate these plots.
Please note that you would not be expected to generate this. We are using libraries here we do not teach (seaborn and advanced plotting library) and lambda functions, a concept that is an advanced programming concept.
import numpy as np
import seaborn as sns
sns.set_context("paper", font_scale=2)
#make this example reproducible
np.random.seed(0)
#create data
x = np.random.normal(size=10000)
#create normal distribution histogram
#sns.displot(x)
sns.displot(x, kde=True, line_kws={'lw': 3}, facecolor='azure', edgecolor='black', height=5,aspect=1.5)
plt.xlabel('position')
sns.displot(np.random.uniform(size=100000), kde=True, line_kws={'lw': 3}, facecolor='azure', edgecolor='black',height=5,aspect=1.5)
plt.xlabel('position')
sns.displot(np.random.exponential(size=10000), kde=True, line_kws={'lw': 3}, facecolor='azure', edgecolor='black',height=5,aspect=1.5)
plt.xlabel('position')
sample_bimodal = pd.DataFrame({'feature1' : np.random.normal(10, 5, 10000),
'feature2' : np.random.normal(40, 10, 10000),
'feature3' : np.random.randint(0, 2, 10000),
})
sample_bimodal['combined'] = sample_bimodal.apply(lambda x: x.feature1 if (x.feature3 == 0 ) else x.feature2, axis=1)
sns.displot(sample_bimodal['combined'].values, kde=True, line_kws={'lw': 3}, facecolor='azure', edgecolor='black', height=5,aspect=1.5)
plt.xlabel('position')
4.1 The Normal or Gaussian distribution#
The normal distribution is a well-behaved symmetric distribution. On a normal distribution the values that are less than 1 \(\sigma\) away from the mean, \(\mu\), will account for the 68.27% of the dataset. This means the confidence interval is equal to the standard deviation of 1 \(\sigma\) (dark blue shading).
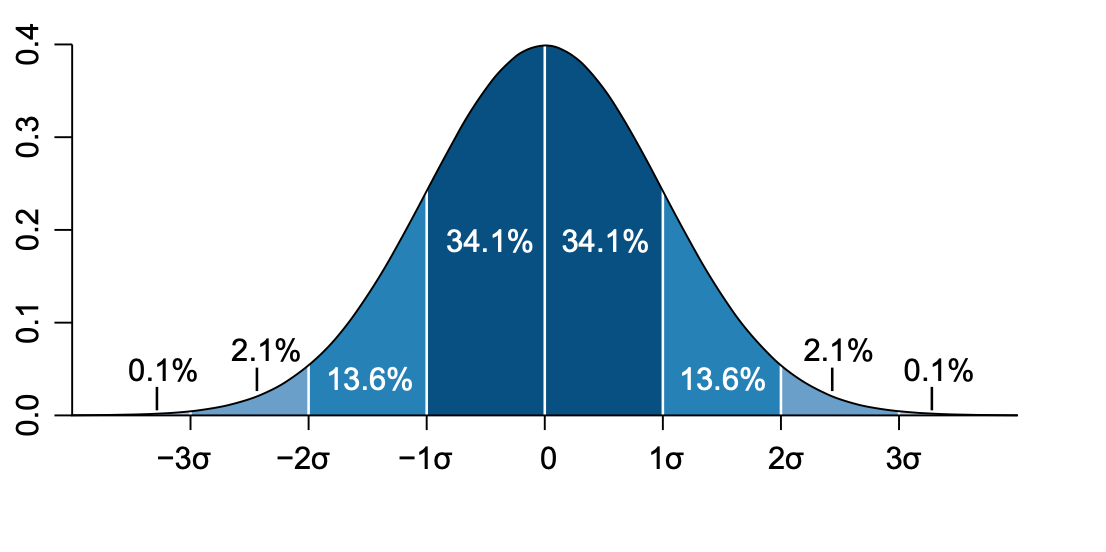
Mathematically, you can write down the probability density function of a normal distribution as:
This looks scarier than it is, as you already know what \(\mu\) and \(\sigma\) are, namely the mean and standard deviation respectively. Writing down the probability density function in this way assumes a continuous set of values of \(x\) and not necessarily a dataset containing \(N\) values. A quick way of notating that a random variable \(X\), such as one measured in an experiment, is normally distributed with mean \(\mu\) and standard deviation \(\sigma\) is:
Generating N data points according to a normal distribution in Python#
You can use the numpy library to generate a normal distribution as follows
mu = 0 # mean
sigma = 0.1 # standard deviation
samples = 10 # number of samples
distribution = np.random.normal(mu, sigma, samples)
print(distribution)
Tasks#
Use the Mentimeter wordcloud below to collect some ideas.
Use Mentimeter to ask for everyday examples to a normal distribution!
# Task:
Mentimeter(vote = 'https://www.menti.com/link_to_question').show()
Mentimeter(result ='https://www.mentimeter.com/app/presentation/link_to_answer').show()
Click here to see solution to Task.
Examples are: - Height - Birth weight - Reaction yields - pipetting volume - …
Use the Mentimeter quiz to give us an answer.
# Task : Yes no answer
Mentimeter(vote = 'https://www.menti.com/link_to_mentimeter').show()
# Answers
Mentimeter(result ='https://www.mentimeter.com/app/presentation/link_to_answer').show()
Click here to see solution to Task.
No, this seems like a good example. Ideally you want pollutants to be zero, therefore the peak should be at zero and you cannot have negative values of pollutants.
Generate the following distributions, plot them, and discuss what you see:
Normal distribution with \(\mu\) = 0 and \(\sigma\)=2
Normal distribution with \(\mu\) = 3 and \(\sigma\) = 0.2
What happens if you change the number of samples? Try 10, 100 or even 10000
Are the mean and standard deviation the same as the input?
Are the mean and median the same?
# Task: Test out the solution in this cell:
Click here to see solution to Task.
# Comparing two distributions
distribution1 = np.random.normal(0, 2, 1000)
distribution2 = np.random.normal(3, 0.2, 1000)
plt.hist(distribution1, bins=50)
plt.hist(distribution2, bins=50)
# Distributions with many samples
dist_low_sample = np.random.normal(0, 2, 10)
dist_med_sample = np.random.normal(0, 2, 100)
dist_high_sample = np.random.normal(0, 2, 10000)
print("low sample: ")
print(f'mean:{np.mean(dist_low_sample):.3f}, median:{np.median(dist_low_sample):.3f}, standard deviation:{np.std(dist_low_sample):.3f}')
print("medium sample: ")
print(f'mean:{np.mean(dist_med_sample):.3f}, median:{np.median(dist_med_sample):.3f}, standard deviation:{np.std(dist_med_sample):.3f}')
print("high sample: ")
print(f'mean:{np.mean(dist_high_sample):.3f}, median:{np.median(dist_high_sample):.3f}, standard deviation:{np.std(dist_high_sample):.3f}')
Write a function called normal_distribution(x, height, mean, sigma) that returns a normal distribution for a set of positions x. Generate data for your distribution using np.random.choice and plot the data.
Here are some suggestions for the input data:
x = np.linsapce(-10,10,100)
height = 12
mean = 0
sigma =1
# Advanced task: Test out the solution in this cell:
Click here to see solution to Task.
def normal_distribution(x,height, mean, sigma):
return height*np.exp(-(x-mean)**2/(2*sigma**2))
x = np.linspace(-10,10,100)
parameters = [12, 0, 1]
p = normal_distribution(x, *parameters)
p = p/p.sum()
samples = np.random.choice(x, p=p, size=100)
plt.hist(samples, density=True)
plt.plot(x,p,'ro:')
4.2 Comparing two distributions#
Let us look at an example dataset of red and white wine to see if we can compare distributions easily.
You will be able to find the datasets in data/winequality-red.csv and data/winequality-white.csv. Both datasets have been taken from here and were first featured in this publication.
Let’s load the two datasets and compare the pH of red and white wines.
# Loading the data
df_red = pd.read_csv("data/winequality-red.csv")
df_whites = pd.read_csv("data/winequality-white.csv", delimiter=';')
Let’s have a look at the column headings:
print(df_whites.columns)
And double check that there is no data missing in the dataset:
print(df_red.isnull().values.any())
print(df_whites.isnull().values.any())
Comparing the distribution of pH between red and white wines#
pH_whites = df_whites['pH']
pH_reds = df_red['pH']
plt.hist(pH_whites, bins=50, color='gray', alpha=0.5, label="white")
plt.hist(pH_reds, bins=50, color='red', alpha=0.5, label="red")
plt.xlabel('pH')
plt.ylabel('counts')
plt.legend();
The two distributions look different, but is there a better way at looking them?
A boxplot can graphically show the locality, spread and distribution of the data#
A box plot lets you quickly examine multiple distributions graphically
It is great for comparing distributions
You don’t have to make a choice on number of bins
You can immediately see the median, 50% region of the data, quantiles, as well as outliers.
You can also display the mean and median giving you an idea how skewed the data is and whether assuming that data is normally distributed is a good assumption.
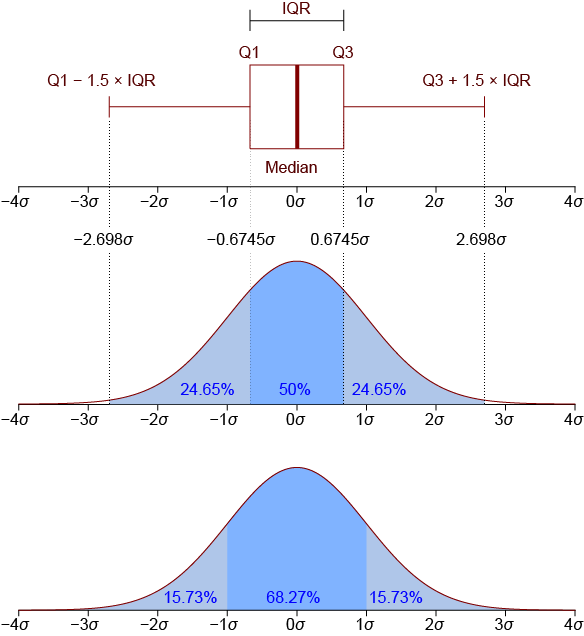
By Jhguch at en.wikipedia, CC BY-SA 2.5, https://commons.wikimedia.org/w/index.php?curid=14524285
Here is an example of how the boxplot in matplotlib will look like:
Let’s plot the pH data as a boxplot#
columns = [pH_whites, pH_reds]
fig, ax = plt.subplots()
# in matplotlib you can use the boxplot function and set the show means to True
ax.boxplot(columns, showmeans=True)
plt.xticks([1, 2], ["pH whites", "pH reds"], rotation=90)
plt.show()
# the orange lines represent the median of the data and the green triangles the mean
From the boxplot we can see that the mean and median are quite similar. We could not see this on the distribution plot before. Now let’s look at the actual values for the means, medians and standard deviations?
print(f'The mean pH is {np.mean(pH_whites):.3f}, \
the median pH is {np.median(pH_whites):.3f}, \
and the standard deviation in white wines is {np.std(pH_whites):.3f}.')
print(f'The mean pH is {np.mean(pH_reds):.3f}, \
the median pH is {np.median(pH_reds):.3f}, \
and the standard deviation in red wines is {np.std(pH_reds):.3f}.')
These numbers look quite similar. Can we statistically say if they come from a different underlying distribution?#
4.3 The Student’s t-test#
When to use a t-test?#
A t-test is a parametric test of difference, meaning that the underlying data is as follows:
Your samples of the data are independent.
They are approximately normally distributed.
Have a similar amount of variance.
You can also only compare means of two groups. If want to compare multiple means not in a pairwise fashion there are other tests. In the same spirit, if the above assumptions do not fit, you can use a nonparametric test such as the Wilcoxon Signed Rank test. A lot of these tests are implemented in Python.
Performing a t-test#
In a t-test you are estimating the true difference between two dataset means. This is done by using the ratio of the difference in dataset means over the pooled standard error of the two datasets. Mathematically you can write the student t-test as:
As before \(\mu_1\) and \(\mu_2\) represent the means of the respective two datasets, \(N_1\)=\(N_2\)=\(N\) and are the number of samples and \(s_p\) is the pooled standard deviation of the datasets. There is a more general form with the two dataset having different sample sizes too!
Pooled standard deviations of a dataset#
The pooled standard deviation is a method for estimating a single standard deviation to represent all independent samples or groups in your study when they are assumed to come from populations with a common standard deviation. The pooled standard deviation is the average spread of all data points about their group mean (not the overall mean). It is a weighted average of each group’s standard deviation.
Mathematically you can write the pooled standard deviation as:
\(S_p = \sqrt{\frac{\sigma_1^2+\sigma_2^2}{2}}\)
What does the calculated t-value mean?#
A large t-value means that the difference between the means of the two datasets is greater than the pooled standard error, which means there is likely a significant difference between the two datasets.
Typically you would compare your t-value to tabulated t-values to decided if you accept the null hypothesis. Have a look here for more details: https://www.statology.org/here-is-how-to-find-the-p-value-from-the-t-distribution-table/
The Null hypothesis and tabulated data#
The hypothesis you are testing against, is that the difference in means between two datasets is 0. When you perform a t-test with Python, you will get a p-value returned, giving you the probability of how likely is it to see this result by chance. The p-value is a proportion: if your p-value is 0.05, that means that 5% of the time you would see a test statistic at least as extreme as the one you found if the null hypothesis was true.
Let’s have a look at using the t-test for our wine dataset:
Performing a two sample t-test#
Previously we have seen that our data is approximately normally distributed. We also want to make sure that our ratio of variances of the two datasets is less than 4:1. So we start with that.
ratio = np.var(pH_reds)/np.var(pH_whites)
print(ratio)
## Looks like we are good to go with our t-test
# We are using scipy stats library to peform the t-test
import scipy.stats as stats
t_test_out = stats.ttest_ind(a=pH_reds, b= pH_whites, equal_var = True)
print(t_test_out)
Hypothesis reminder:#
H0 => \(\mu_1\) = \(\mu_2\) (population mean of dataset1 is equal to dataset2)
HA => \(\mu_1 \ne \mu_2\) (population mean of dataset1 is different from dataset2)
The p-value is smaller than alpha=0.05 means we can reject the null hypothesis (H0). There is sufficient evidence that the mean pH of white wine is different to the mean pH of red wine in the dataset.
Tasks#
Compute the following:
Histogram of the density
Boxplot of the density
After you are sure you can carry out a t-test, carry it out.
What happens if you only take every 200th data point? What does the null hypothesis of the t-test say?
# Task 1: Test out the solution in this cell:
Click here to see solution to Task.
# Histograms
density_whites = df_whites['density']
density_reds = df_red['density']
plt.hist(density_whites, bins=50, alpha=0.5)
plt.hist(density_reds, bins=50, color='green', alpha=0.5)
plt.xlabel('density')
plt.ylabel('counts')
# Box plots
columns = [density_whites, density_reds]
fig, ax = plt.subplots()
ax.boxplot(columns, showmeans=True) # in matplotlib you can use the boxplot function and set the show means to True
plt.xticks([1, 2], ["density whites", "density reds"], rotation=90)
plt.show()
# t-testing
print(np.var(density_reds)/np.var(density_whites))
print("yes we can do a t-test")
t_test = stats.ttest_ind(a=density_reds, b= density_whites, equal_var = True)
print(t_test)
t_test_sub_sample = stats.ttest_ind(a=density_reds[::200], b= density_whites[::200], equal_var = True)
print(t_test_sub_sample)
print("The two density distributions have two different means for the original dataset. When you subsample heavily the null hypothesis does not hold true anymore.")
Compute the following:
Histogram of the residual sugar
Boxplot of the residual sugar
Is the data suitable for a t-test? If so, carry out a t-test.
# Task 2: Test out the solution in this cell:
Click here to see solution to Task.
# Histograms
sugar_whites = df_whites['residual sugar']
sugar_reds = df_red['residual sugar']
plt.hist(sugar_whites, bins=50, alpha=0.5)
plt.hist(sugar_reds, bins=50, color='green', alpha=0.5)
plt.xlabel('residual sugar')
plt.ylabel('counts')
# Box plots
columns = [sugar_whites, sugar_reds]
fig, ax = plt.subplots()
ax.boxplot(columns, showmeans=True) # in matplotlib you can use the boxplot function and set the show means to True
plt.xticks([1, 2], ["residual sugar whites", "residual sugar reds"], rotation=90)
plt.show()
# t-testing
print(np.var(sugar_reds)/np.var(sugar_whites))
print("No we cannot do a t-test")
# Task 3: Test out the solution in this cell:
Break#
